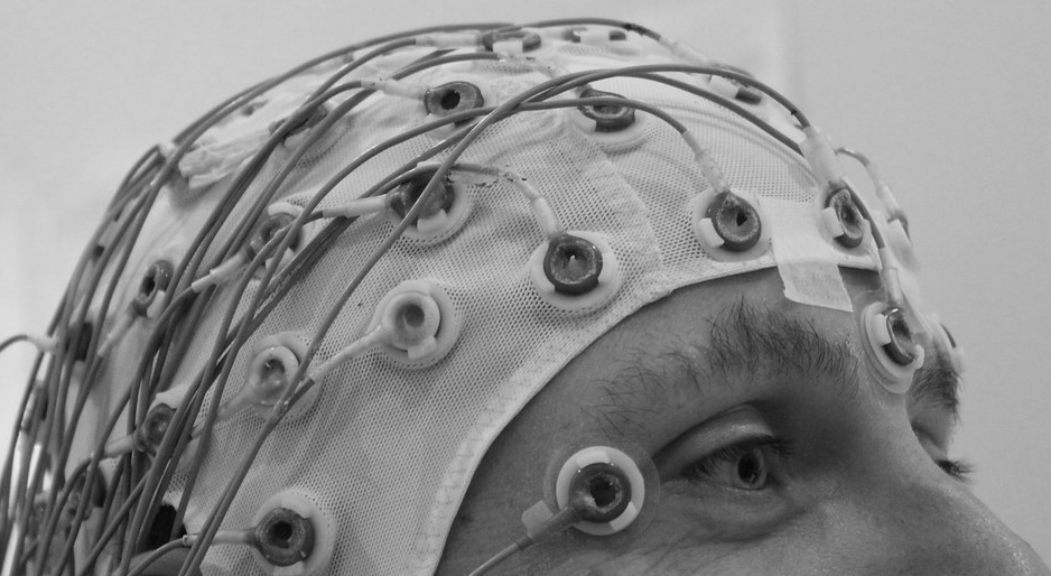
La mente humana genera una cantidad ingente de datos que las empresas tecnológicas se afanarán en aprovechar. Nuevas aplicaciones dificultarán la protección de la privacidad.
Stephen Rainey y Christoph Bublitz – El incremento del uso de datos generados por el cerebro plantea preocupaciones sobre la privacidad, ya sea por su uso en contextos de investigación, en dispositivos médicos o en el creciente sector de tecnologías de monitorización de la actividad cerebral del consumidor. Algunos exigen una regulación internacional, especialmente porque la neurotecnología aplicada al consumo está a punto de penetrar ampliamente en el mercado. En este artículo nos fijaremos en la regulación de los datos generados por la actividad cerebral prevista en el Reglamento General de Protección de Datos (RGPD) y sugerir una modificación que proporcione mejor protección.
En medicina está aumentando el uso de dispositivos de monitorización cerebral, por ejemplo mediante interfaces cerebro-máquina que permiten la comunicación y el control de prótesis neuronales o motoras. Pero también está en desarrollo una gama de dispositivos con aplicaciones no médicas, que van desde juegos a herramientas para el ámbito profesional.
Las soluciones que se comercializan actualmente, por ejemplo Emotiv o Neurosky, todavía no están muy difundidas. Podría deberse a la falta de aplicaciones, a problemas de usabilidad o, tal vez, a que no se percibe su necesidad. Sin embargo, diversas empresas tecnológicas han anunciado su interés por éste ámbito y han invertido significativas cantidades de dinero. Kernel, una compañía multimillonaria con sede en Los Ángeles y con tres años de antigüedad, quiere «hackear el cerebro humano«. Recientemente se alió con Facebook que, a su vez, tiene interés en desarrollar un método que permita controlar directamente dispositivos a partir de datos generados por el cerebro (lo está haciendo en su laboratorio ‘Building 8’). Mientras tanto, Neuralink, de Elon Musk, apunta a ‘fusionar el cerebro con la Inteligencia Artificial’‘ por medio de un ‘casco mágico‘. Lo que sea que esto signifique, es probable que se base en la monitorización y estimulación del cerebro.
No será algo pasajero. Se está invirtiendo mucho dinero
Estas aplicaciones ponen de manifiesto la intención de desarrollar interfaces neuronales para vincular directamente los ordenadores con el cerebro. Queda por ver si tendrán éxito. Pero es evidente que, en el futuro, los Brain-Computer Interface (BCI) existirán. Con el respaldo financiero de las empresas tecnológicas y el apoyo de figuras del alto nivel como Musk es poco probable que sean algo pasajero.
Estos dispositivos no detectan directamente el pensamiento pero registran y procesan la actividad cerebral. Al hacerlo, generan muchos datos, pero debido a la gran cantidad recopilada, sólo un subconjunto de ellos será directamente relevante para el funcionamiento de los dispositivos que controlarán. Ahí podría producirse una especie de fuga de datos neuronales, lo cual plantea interesantes interrogantes regulatorios.
Parece bastante claro que los gigantes de la tecnología estarán muy interesados en usar esta mina de datos. Supondrá un activo para sus actividades y intereses actuales, intereses que incluyen perfilar el comportamiento humano a través de la datificación.
Podemos fácilmente imaginar una idea distópica en la que una empresa – llamémosla Schmoogle– cree un juego y analice la reacción de sus jugadores. Mediría directamente la actividad cerebral de los jugadores a medida que reaccionasen a determinados estímulos al navegar por sus mundos virtuales. Al hacerlo, los jugadores alimentarían una base de datos de señales cerebrales.
También una red social – llamémosla Schmacebook-, mediante el mismo planteamiento, podría observar cómo reaccionamos ante cada publicación de manera mucho más directa que haciéndolo marcando sólo pulgares arriba o abajo. La grabación de datos cerebrales, mediante un casco u algún otro medio, podría aportar una visión neurofisiológica a las publicaciones de la abuela, la CNN o un partido político.
No leerán el pensamiento pero identificarán preferencias y reacciones emocionales
Mediante estos métodos se podría comprobar el tipo de estado mental de cada persona, como sus preferencias concretas y sus reacciones emocionales a todo tipo de estímulos. Una onda cerebral específica, la llamada onda P-300, puede revelar si, para una persona, un estímulo es nuevo o si le resulta familiar (durante muchos años se ha investigado su uso con fines forenses). Las preferencias o predisposiciones pueden inferirse sin que los usuarios tengan que hacer nada especial. Sólo deben usar su ordenador a través del BCI. Puede que ni siquiera sean conscientes de ello. Estas reacciones tampoco están bajo el control consciente de la persona, por lo que, en cierto sentido, se conectan con el inconsciente. Sin embargo, queremos puntualizar que los temores a que se pueda leer el pensamiento o interpretar el contenido de los estados mentales son prematuros.
Estos datos son, por supuesto, de gran interés para mucha gente, incluidas las empresas cuyo poder se basa en la tecnología y los datos. Una información de esta índole tendría para ellas un valor innegable. Y eso podría generar problemas. Los datos cerebrales se pueden instrumentalizar fácilmente de varias maneras, sobre todo en el contexto de la creciente complejidad algorítmica y la normalización del big data.
¿Qué hacer? La parte normativa
El concepto ético y legal que guía la recopilación de datos cerebrales es la privacidad, y aquí hablamos en términos de privacidad mental. Esta idea está empezando a captar la atención de los académicos, tanto de los especialista en ética como de los juristas. Definir un concepto sólido de privacidad mental, y sus límites, será clave para una regulación adecuada de los datos del cerebro. En este punto queremos llamar la atención sobre un instrumento, muy familiar en la UE, ya que ha transformado la navegación en la red mediante un clic continuo en los botones de consentimiento: el Reglamento General de Protección de Datos (RGPD). ¿Qué relación tiene el RGPD con las cuestiones planteadas por la grabación de datos cerebrales?
En sus disposiciones, el RGPD considera a los individuos como «sujetos de datos» y garantiza sus derechos ante cualquier dato personal que pueda identificarles. Esta es una consideración importante. Significa que, por ejemplo, las empresas que conservan sus datos de contacto deben tener especial cuidado al compartirlos, almacenarlos y eliminarlos. Diferentes tipos de datos comportan vías diferentes de protección, dependiendo de lo sensibles que sean. Los datos de salud requieren niveles de protección más altos dado que, a partir de ellos, se puede obtener información muy sensible acerca de una persona. Los datos del cerebro, que se obtienen a través de dispositivos médicos utilizando, por ejemplo, el BCI en la rehabilitación motora o del habla, se consideran habitualmente datos de salud. Sin embargo, si provienen de neurotecnología aplicada al consumo y la monitorización del tipo previsto por Facebook, Kernel y Neuralink, no lo son.

Queremos sugerir aquí que los datos del cerebro obtenidos a partir de cualquier tipo de grabación fisiológica se consideren ‘datos médicos’ y sean tratados en consecuencia. Se les otorgaría, así, un nivel alto de protección. El motivo se debe a que los datos del cerebro son tan sensibles como el resto de tipos incluidos en la categoría de protección especial. Además, creemos que la medición del cuerpo y la mente fue concebida por los redactores del RGDP como un caso de datos de salud, una categoría que debe interpretarse en sentido amplio. Los redactores quizás no tuvieron presente la expansión de las grabaciones cerebrales no médicas.
Como consecuencia, el registro de dichos datos, y todos sus usos posteriores, requerirían el consentimiento del interesado (con la excepción de diez casos especiales enumerados por el RGDP). Esto proporcionaría una primera capa de protección.
Es necesario tratar los datos generados por el cerebro con los niveles más altos de protección
Pero puede que no sea suficiente. Como todos sabemos por la forma en que utilizamos nuestros teléfonos inteligentes, los individuos consienten fácilmente que sus datos se registren y se utilicen, al menos si obtienen algo útil a cambio. Pagamos con los datos. Es muy probable que éste también sea el modelo de negocio para los datos del cerebro. Y para ello, el actual RGDP no ofrece soluciones satisfactorias. Podría ser necesario un nuevo marco regulatorio para todo tipo de datos, incluidos, entre otros, los registrados por el cerebro. Hay que tener en cuenta el creciente papel que desempeña el procesamiento algorítmico, por lo que no es fácil predecir el uso que se puede dar a tanta cantidad de datos.
Los datos registrados para un propósito determinado podrían quedar almacenados en una memoria caché y futuros algoritmos podrían revelar información no prevista sobre el ‘sujeto de los datos’. Esta posibilidad, más allá de considerar la naturaleza especial de los datos obtenidos del cerebro (neuroesencialismo), debería comportar las protecciones más altas.
Stephen Rainey y Christoph Bublitz
Este artículo se publicó originalmente en el blog Practical Ethics de la Universidad de Oxford con el título: Regulating The Untapped Trove Of Brain Data

Stephen Rainey es investigador del Oxford Uheiro Center for Practical Ethics.
Christoph Bublitz es investigador de la Facultad de Derecho de la Universidad de Hamburgo
2 comments
«El sueño de la razón genera monstruos». En este caso, lo primero que preguntaría a quienes desarrollan estas tecnologías es «Para qué» lo hacen. Porque podrían escoger no desarrollarlas. Pienso que lo más probable es que sus respuestas fueran decepcionantes (sobre el progreso, o cosas así) o alarmantes. En todo caso, me gustaría leerlas o escucharlas.
Gracias por tu comentario. Entiendo absolutamente la pregunta, ‘por qué’.
En muchos casos, la neurotecnología se elabora en laboratorios científicos, por ejemplo en universidades. A veces, esto es parte de la investigación básica, sobre el cerebro o, a veces, de la investigación médica. La neurotecnología puede ayudar con la epilepsia, el parkinson y tal vez con afecciones como la depresión. La recopilación de datos aquí tiene riesgos, pero las recompensas son claras y los laboratorios están bien regulados.
Fuera de estos contextos, la regulación es menos seria. Pero todavía existen riesgos y las recompensas son menos obvias. La pregunta cada vez es: ¿Cui bono? En casos comerciales, la respuesta corta a la pregunta, ‘¿para qué?’ es ‘dinero.’ Los datos son un activo. Por lo tanto, la compra y venta de datos se convierte en un objetivo para desarrollarlos. También, vanidad. Nadie cree que Elon Musk sea un personaje tímido, ávido de privacidad. Otros ‘neurohackers’ quieren utilizar el conocimiento sobre sus cerebros para explorar las posibilidades de la experiencia humana. Quizás esto sea diferente.
Deberíamos hacernos preguntas sobre cuándo se trasplantan las tecnologías de un contexto a otro, como de lo médico a lo comercial. En cada caso plantean cuestiones importantes.